Receiver operating characteristic (ROC) curves, and the area under the ROC curve (AUROC), are tools for evaluating the usefulness of a measurement or risk score for screening, diagnosis, or prediction of a future event.
One common interpretation of the AUROC is the following:
The AUROC is the probability that, in a random pairing of a disease patient with a non-disease patient, the disease patient has the higher score.1
In other words, the AUROC is the probability of concordance — the probability of agreement between the score and disease status.
I’ve been aware of this interpretation for a long time without seeing from the construction of the ROC curve why this would be the case, and without knowing how one demonstrates it mathematically. With the help of an excellent book,2 I’ve put together some notes on the topic.
ROC curves and AUROC
First, a quick review of the problem setting. Some type of score, the values of which can be unambiguously ordered from lowest to highest, is measured or calculated from each patient in a population. The purpose of the score is to represent, or correlate with, a patient’s risk of having a particular disease. A reference (“gold”) standard method is used to determine each patient’s disease status.
An ROC curve is constructed by computing the true positive fraction (TPF) and false positive fraction (FPF) for each possible threshold of the score, where the threshold is used to classify patients as “positive” (higher scores) vs “negative” (lower scores).
TPF is the same as sensitivity, and FPF is the same as \(1-\)specificity:
TPF = Sensitivity = fraction of patients labeled as positive, among those with disease
FPF = \(1-\)Specificity = fraction of patients labeled as positive, among those without disease
## Warning: A numeric `legend.position` argument in `theme()` was deprecated in ggplot2
## 3.5.0.
## ℹ Please use the `legend.position.inside` argument of `theme()` instead.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.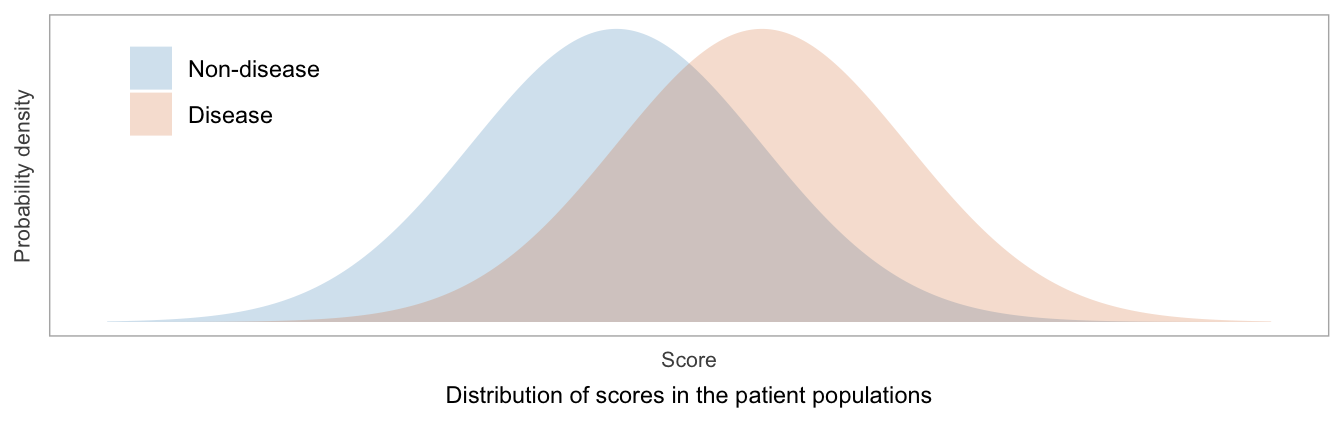
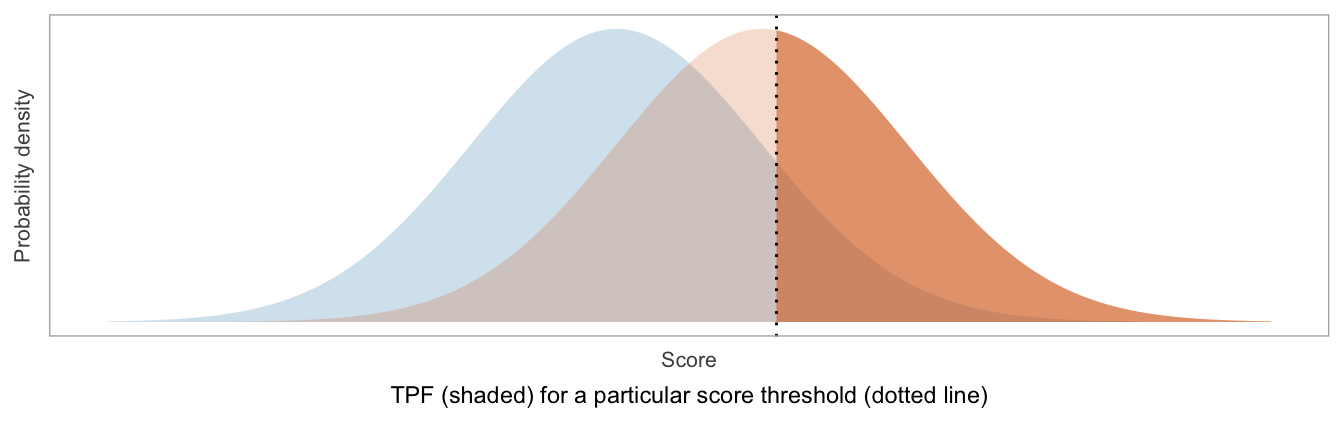
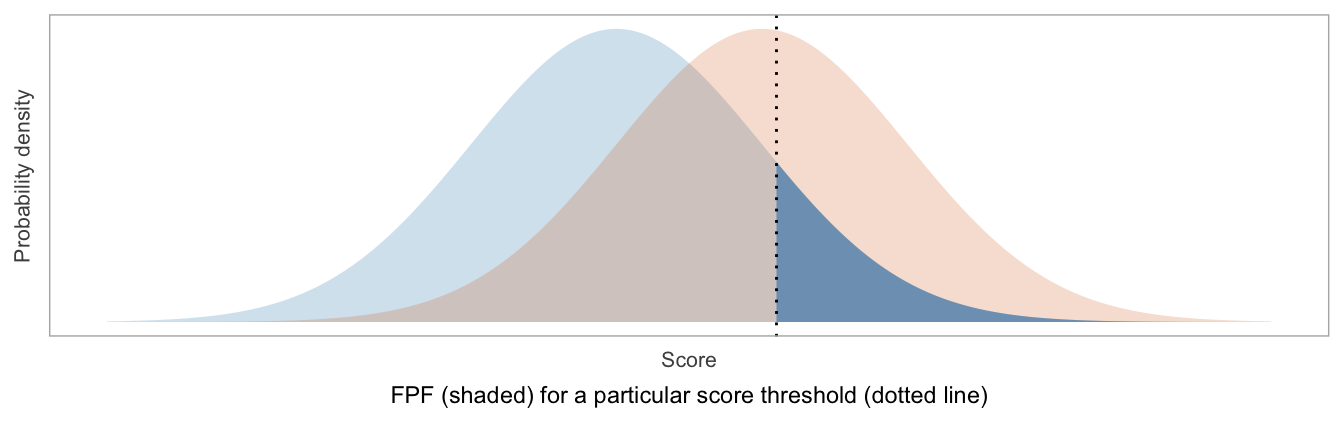
The ROC curve is formed from plotting TPF vs FPF. As the score threshold decreases, the TPF and FPF each increase from 0 to 1. In terms of (FPF, TPF) coordinates, the ROC curve goes from (0, 0) to (1, 1).
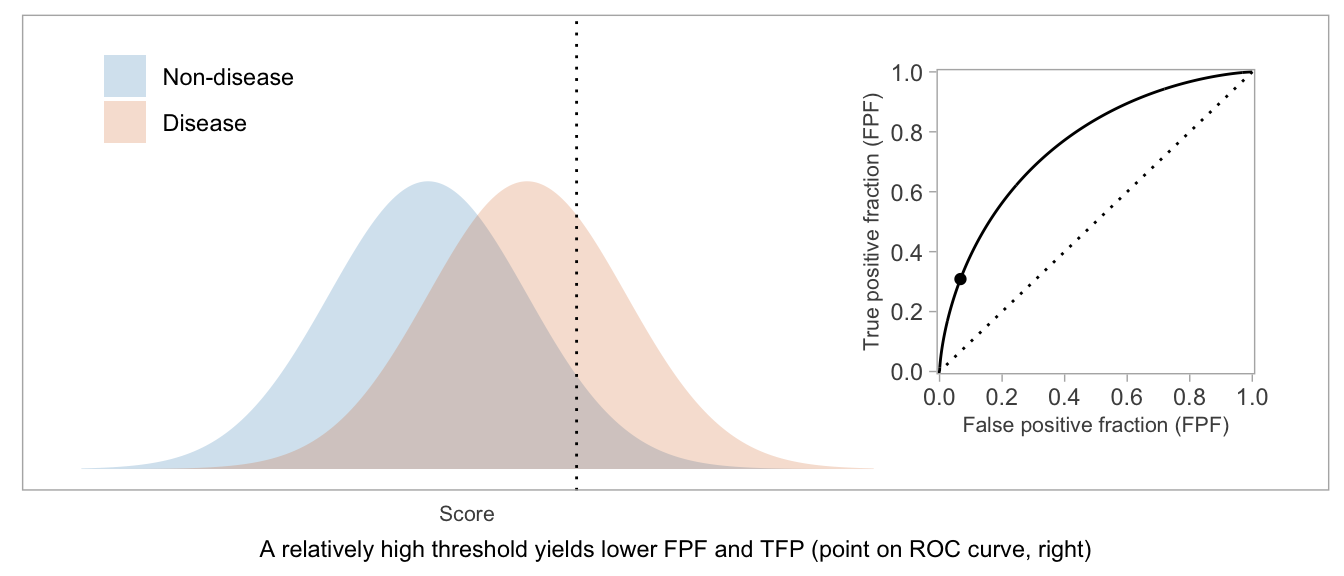
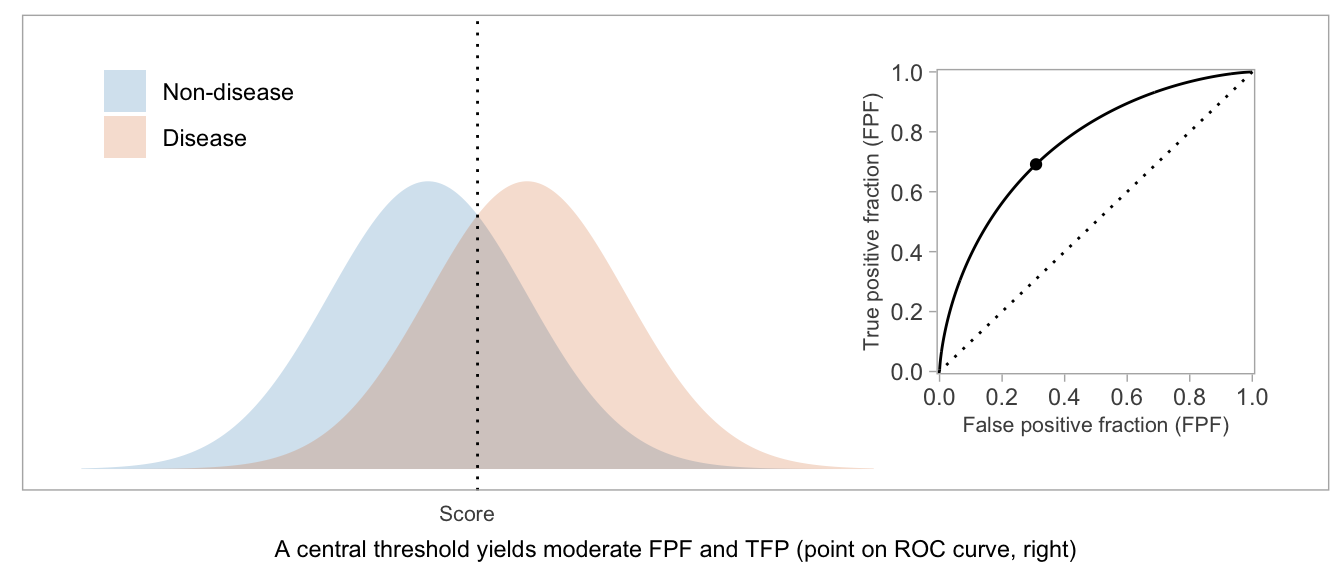
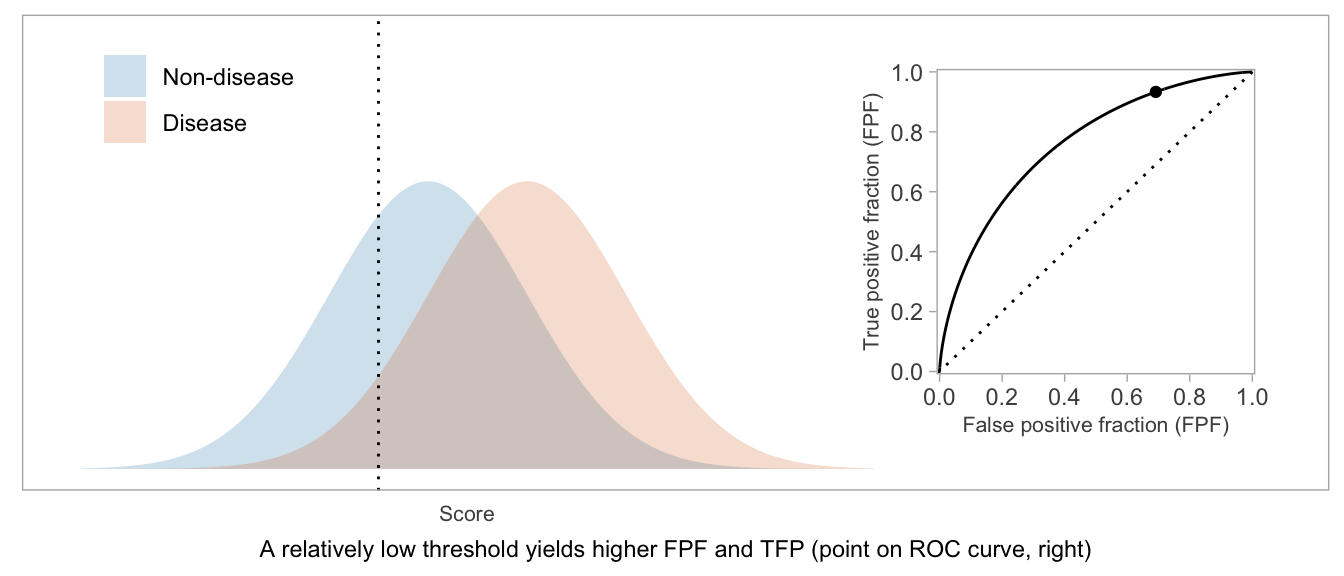
If a score will be used in a dichotomous manner (positive vs negative), the ROC curve can be used as a visual aid in weighing TPF vs FPF and choosing a desirable threshold.
If a score will be used as-is, without dichotomization, or if there’s not yet an accepted threshold for positive classification, then the whole curve is potentially relevant. The AUROC — which is exactly what the name suggests: the area between the \(x\)-axis and the (FPF, TPF) curve — is a way to summarize the curve and condense the (FPF, TPF) values into a single number.
Higher AUROC is desirable. AUROC = 0.5 indicates a useless score, and AUROC = 1 indicates a score that can perfectly separate disease from non-disease patients.
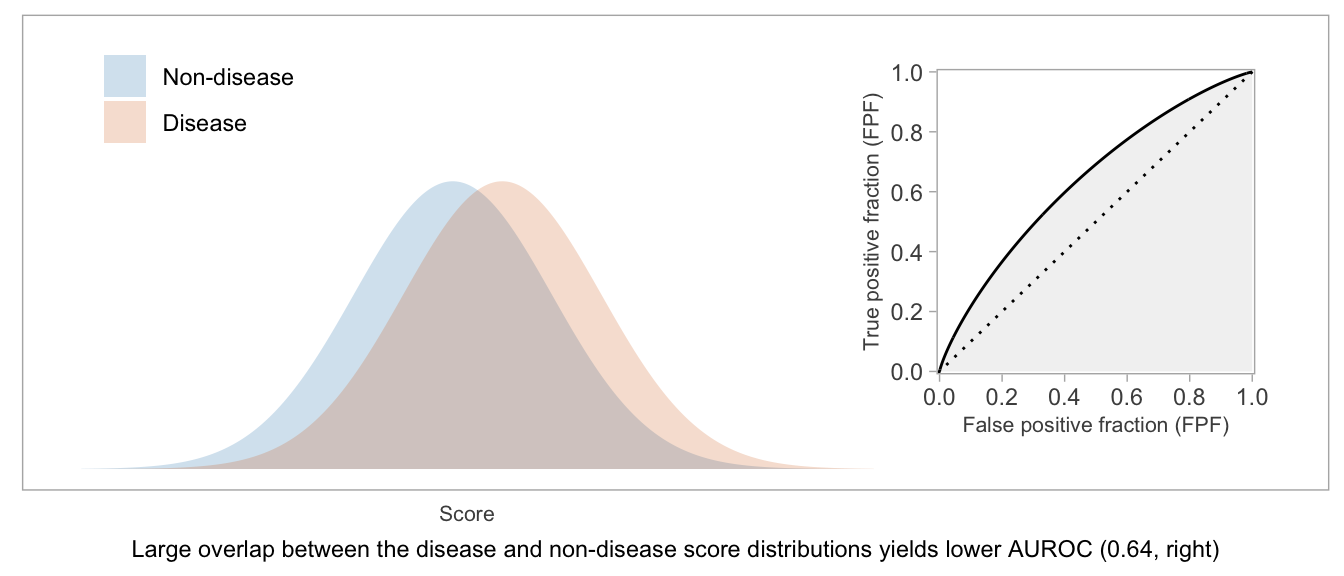
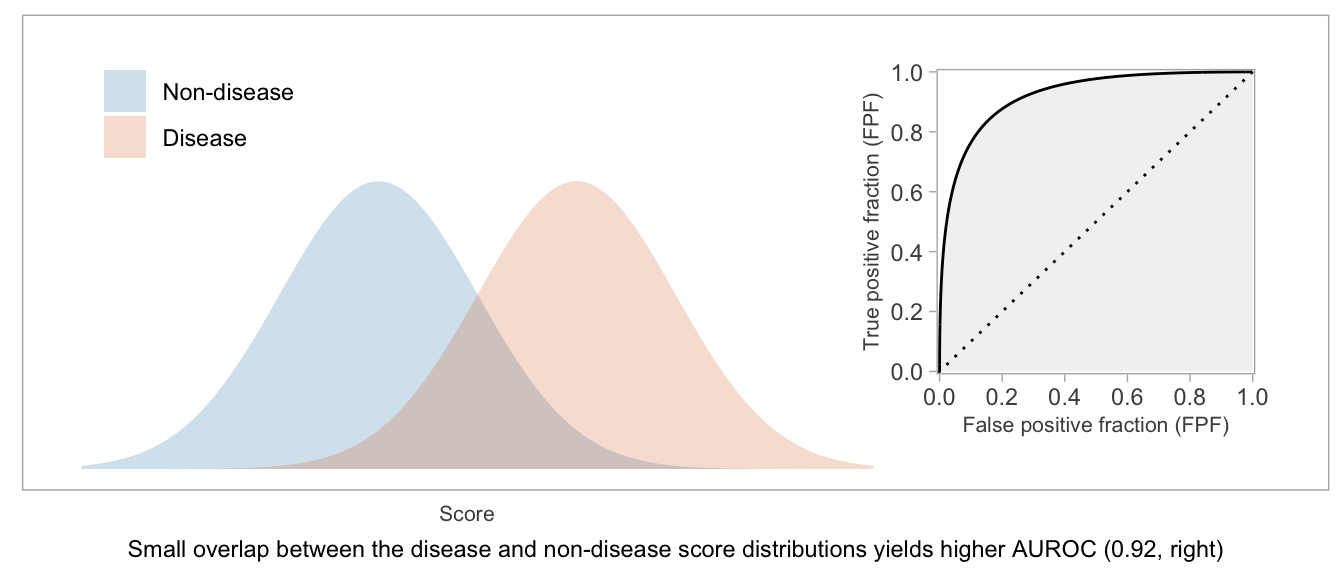
Two interpretations
In the book cited above, Pepe writes,3
The AUC has an interesting interpretation. It is equal to the probability that test results from a randomly selected pair of diseased and non-diseased subjects are correctly ordered, namely \(P[Y_D > Y_{\overline{D}}]\)… Although the interpretation of the AUC as the probability of ‘correctly ordering diseased and non-diseased subjects’ is interesting, it does not necessarily provide the best interpretation of this summary measure. The clinical relevance of the correct ordering is not particularly compelling for the applications that we consider… We prefer to interpret the AUC as an average TPF, averaged uniformly over the whole range of false positive fractions in (0,1).
The interpretation of AUROC as concordance probability is contrasted with an interpretation as an average TPF (sensitivity). While both interpretations are equally correct in a mathematical sense, non-mathematical people may find one view more meaningful than the other, so I’m glad to have come across these passages in the book.
For my own understanding, I found a view of the AUROC in which the equivalence of the two interpretations is so apparent that there’s hardly any need to distinguish between them.
As concordance probability
Consider how one might conduct a study or simulation to determine the concordance probability for a score. Start by randomly selecting one non-disease patient, and suppose their score is \(s\). Now randomly select a disease patient, and suppose their score is \(t\). Count this pair of scores as concordant if \(t > s\).
Repeating this sufficiently many times, and computing the fraction of pairs having concordant scores will yield a precise estimate of the concordance probability.
Now, when you randomly select a non-disease patient, you are randomly selecting a score from the distribution of scores in the non-disease population. If you consider that score to be the threshold defining positive vs negative scores, there is an associated FPF. What is the FPF for score threshold \(s\)? It’s the fraction of non-disease patients who have scores greater than \(s\).
We chose to sample non-disease patients randomly, giving each patient the same probability of being selected. What does this mean in terms of sampling from the possible FPF values? We’re also giving each possible FPF equal probability of being selected. In other words, when we randomly select non-disease patients, the FPF values associated with the patients’ scores will be uniformly distributed between 0 and 1.4
Next, consider the randomly selected disease patient whose score is \(t\). The score has been selected randomly from the distribution of disease patient scores. By the same reasoning as above, when we consider the score a threshold with a corresponding TPF, over repeated sampling, these TPF values will be distributed uniformly between 0 and 1. Note that higher \(t\) translates into lower TPF.
By translating each sampled \((s, t)\) pair into the corresponding (FPF, TPF) values, we can map each sampled pair of patients onto an \((x, y)\) coordinate in the coordinate space of the ROC curve.
Because the \(x\) and \(y\) coordinates each are uniformly distributed between 0 and 1, the \((x, y)\) points representing the pairs of patients will be uniformly distributed over the unit square bound by \((0, 0)\), \((1, 0)\), \((1, 1)\), and \((0, 1)\).
Now we can consider how the locations of these points signify concordance of the corresponding patient scores. A comparison of the scores \(t\) and \(s\) yields a comparison of the TPF for a threshold of \(t\) compared to the FPF for a threshold of \(s\), which in turn implies whether the \((x, y)\) point lies above, on, or below the ROC curve. Consider any fixed non-disease score of \(s\) and the point on the ROC curve defined by a threshold of \(s\).
- If \(t = s\), the TPF for a threshold of \(t\) is equal to the TPF for a threshold of \(s\), so the \(y\) coordinate of a patient pair with \(t = s\) is equal to the \(y\) coordinate of the ROC curve where the \(x\) coordinate is determined by the threshold \(s\).
- When \(t < s\), the TPF for a threshold of \(t\) must be higher than the TPF when the threshold was \(t = s\), so the \(y\) coordinate of a patient pair with \(t < s\) must be higher than the \(y\) coordinate of the ROC curve.
- When \(t > s\), the TPF for a threshold of \(t\) must be lower than the TPF when the threshold was \(t = s\), so the \(y\) coordinate of a patient pair with \(t > s\) must be lower than the \(y\) coordinate of the ROC curve.
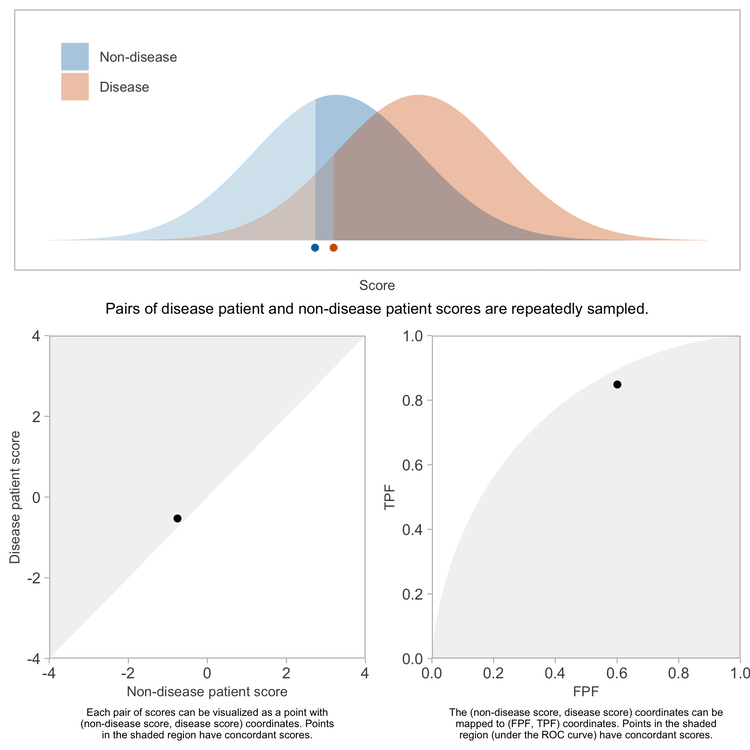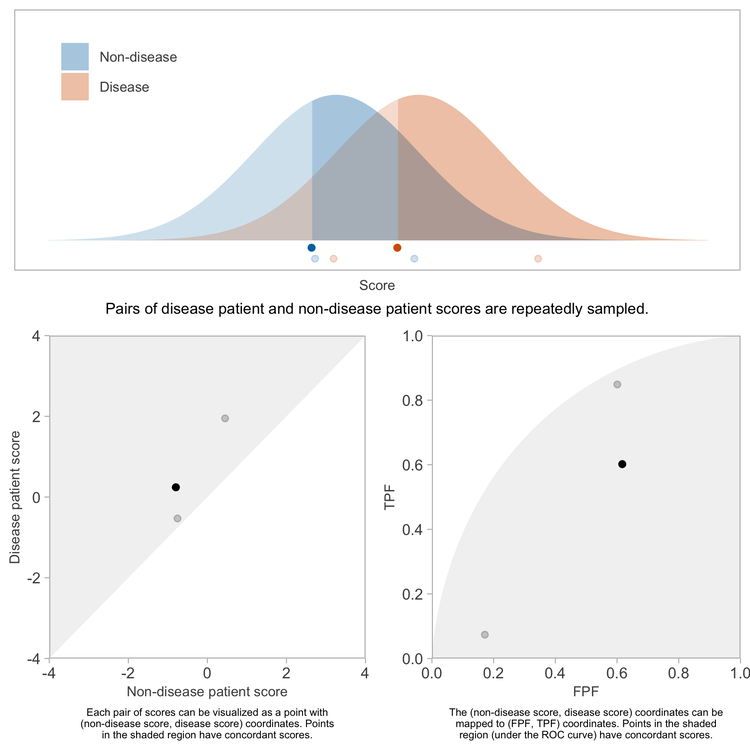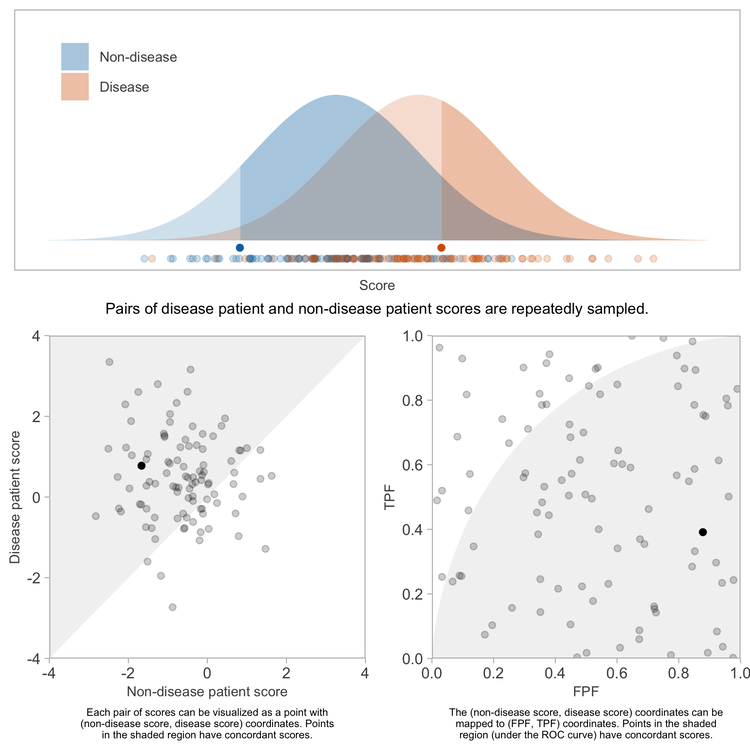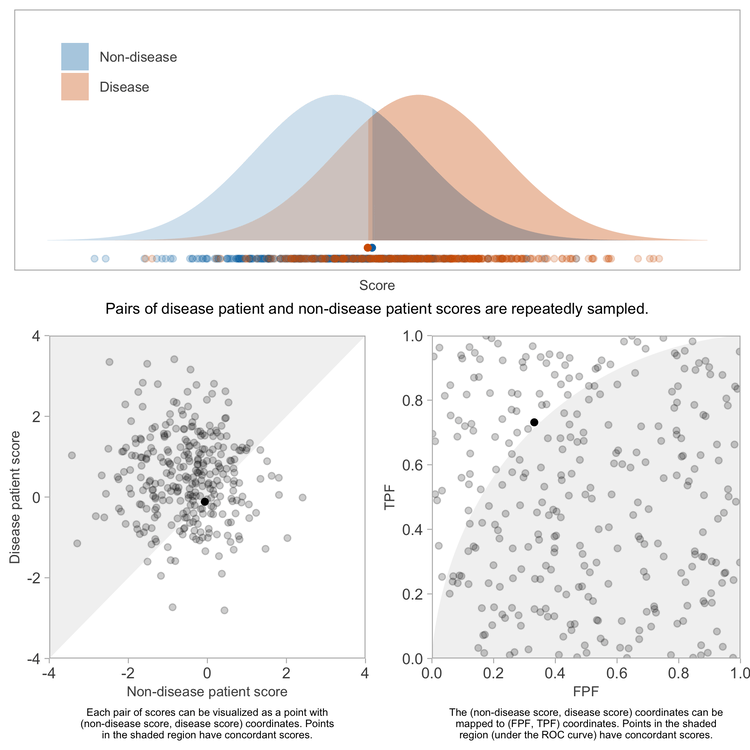
The patient pairs with concordant scores, \(t > s\), are those whose corresponding points on the ROC coordinate space are below the ROC curve. Because the patient pairs are uniformly distributed over that coordinate space (a unit square), the proportion of pairs with concordant scores — or rather, the limit of the proportion as we sample infinitely many pairs of patients — will be equal to the proportion of area within that unit square lying under the ROC curve, which is equal to the AUROC itself because the denominator of the proportion — the area of the bounding square — is 1.
As average TPF
The AUROC is an average TPF (sensitivity) in the following sense.
The ROC curve plots TPF as a function of FPF. The mean, or average, value of a non-negative function, on the domain between \(a\) and \(b\), is the integral of the function divided by \(b-a\).
The AUROC is the integral of the TPF function over the domain of FPF (the interval from 0 to 1), divided by \(1-0=1\). Therefore, the AUROC can be viewed as average TPF for the dichotomized score, averaging over the full range of FPF values and giving equal weight to each FPF. We can imagine picking random \(x\) coordinates (FPF or specificity values) between 0 and 1, then looking up the corresponding \(y\) coordinates (TPF or sensitivity values) and taking their average.
Equivalence of the two interpretations
The scheme above for connecting AUROC to the concordance probability requires only a slight modification to link it to the “average sensitivity” interpretation.
Simply imagine grouping the sampled pairs of patients by their FPF (\(x\)) coordinates after mapping them to the (FPF, TPF) coordinate space. For any given group, suppose the non-disease patients all have scores approximately equal to \(s\); the proportion of concordant pairs in that group is the proportion of disease patient scores greater than \(s\), which is the TPF for threshold \(s\). An average of those proportions, across different values of \(s\), is the same as the overall proportion of concordant pairs because each FPF-based group will have, on average, the same number of patient pairs.
Thus, the calculation of concordance probability is essentially the same as the calculation of average TPF in this scheme, and both are equal to the AUROC.
Formal proof
The equivalence of AUROC, average TPF, and the concordance probability can be formally shown in a straightforward manner that, in some ways, mimics the scheme above:
Consider the ROC curve drawn in \((x, y)\) coordinates, with \(x \in [0, 1]\) and \(y \in [0, 1]\). The ROC curve is a function of \(x\), say \(g(x)\). By definition,
\[\begin{equation} \text{AUROC} = \int_0^1 g(x) dx \end{equation}\]
Let \(F_S(s) = \text{P}(S \leq s)\) be the cdf for non-disease patient scores, \(S\) being a randomly drawn non-disease patient score. Let \(F_T(t) = \text{P}(T \leq t)\) be the cdf for disease patient scores, \(T\) being a random disease patient score. Then again by the definition of ROC curve, as the TPF for a given FPF, \(g(x) = \text{P}(T > s)\) for the score \(s\) which satisfies \(\text{P}(S > s) = x\), i.e. \(1 - F_S(s) = x\). Therefore, \(s = F_S^{-1}(1 - x)\) and
\[\begin{equation} g(x) = 1 - F_T(F_S^{-1}(1 - x)) \end{equation}\]
In the integral for the AUROC,
\[\begin{equation} \text{AUROC} = \int_0^1 \left[ 1 - F_T(F_S^{-1}(1 - x)) \right] dx \end{equation}\]
we change variable from \(x\) to \(s = F_S^{-1}(1 - x)\):
\[\begin{align} \text{AUROC} &= \int_{\infty}^{-\infty} \left[ 1 - F_T(s) \right] [-dF_S(s)] \\ &= \int_{-\infty}^{\infty} \left[ 1 - F_T(s) \right] dF_S(s) \end{align}\]
It follows that
\[\begin{align} \text{AUROC} &= \int_{-\infty}^{\infty} \text{P}(T > s) dF_S(s) \\ &= \int_{-\infty}^{\infty} \text{P}(T > s | S = s) dF_S(s) \\ &= \text{P}(T > S) \end{align}\]
which is the concordance probability. The second line is due to the independence of \(S\) and \(T\) (and also expresses AUROC as an average TPF).
Therefore, AUROC = average TPF = concordance probability.
I’ll use terms that would describe many settings in clinical research: a score is obtained for each patient in the population and used to predict whether the patient has a disease or not. A score may be dichotomized into categories of positive and negative. Be aware that different terms might be appropriate for different settings, but the quantitative issues are the same. I’ll assume that a higher score is associated with having disease.↩︎
Pepe, M. S. (2003). The Statistical Evaluation of Medical Tests for Classification and Prediction. New York: Oxford University Press.↩︎
Ibid, p. 77–79.↩︎
Imagine lining up the non-disease patients, equally spaced, along a line between 0 and 1, in order of their score. Choosing a random patient essentially is the same as choosing a random number between 0 and 1, and selecting the patient nearest that number on the line.↩︎